Monitor your scheduled jobs, background tasks, and automated processes with Checkly’s heartbeat monitoring. Unlike traditional active monitoring, heartbeat monitors work passively—they listen for regular “pings” from your tasks to ensure they’re running as expected.
What are Heartbeat Monitors?
Heartbeat monitors are passive monitoring checks that wait for your automated tasks to report their successful completion. When your scheduled job, backup script, or cron job finishes successfully, it sends a simple HTTP request (a “ping”) to Checkly to confirm it ran.
If Checkly doesn’t receive a ping within the expected timeframe, it triggers alerts to notify you that something may have gone wrong.
Heartbeat monitors are perfect for:
- Backup jobs and data exports
- ETL processes and data imports
- Scheduled maintenance scripts
- Newsletter and email campaigns
- Database cleanup tasks
- File processing workflows
How Heartbeat Monitoring Works
The heartbeat monitoring process is straightforward. Once created, your heartbeat monitor provides a unique ping URL. Your tasks should make an HTTP GET or POST request to this URL when they complete successfully.
- Create a monitor - Set up a heartbeat monitor with your expected ping frequency
- Get your ping URL - Checkly provides a unique URL for your task to ping
- Add the ping - Include a simple HTTP request in your task’s success path
- Monitor results - Checkly tracks pings and alerts you if a ping is missed or delayed
Grace Period
The grace period provides extra time before alerting.
For example, a daily backup job scheduled to run at 2:00 PM with a 30-minute grace period will trigger an alert if no ping is received by 2:30 PM.
Choose grace periods based on:
- Normal variance in your job execution time
- Acceptable delay before you need to know about failures
- Time needed for any retries or recovery processes
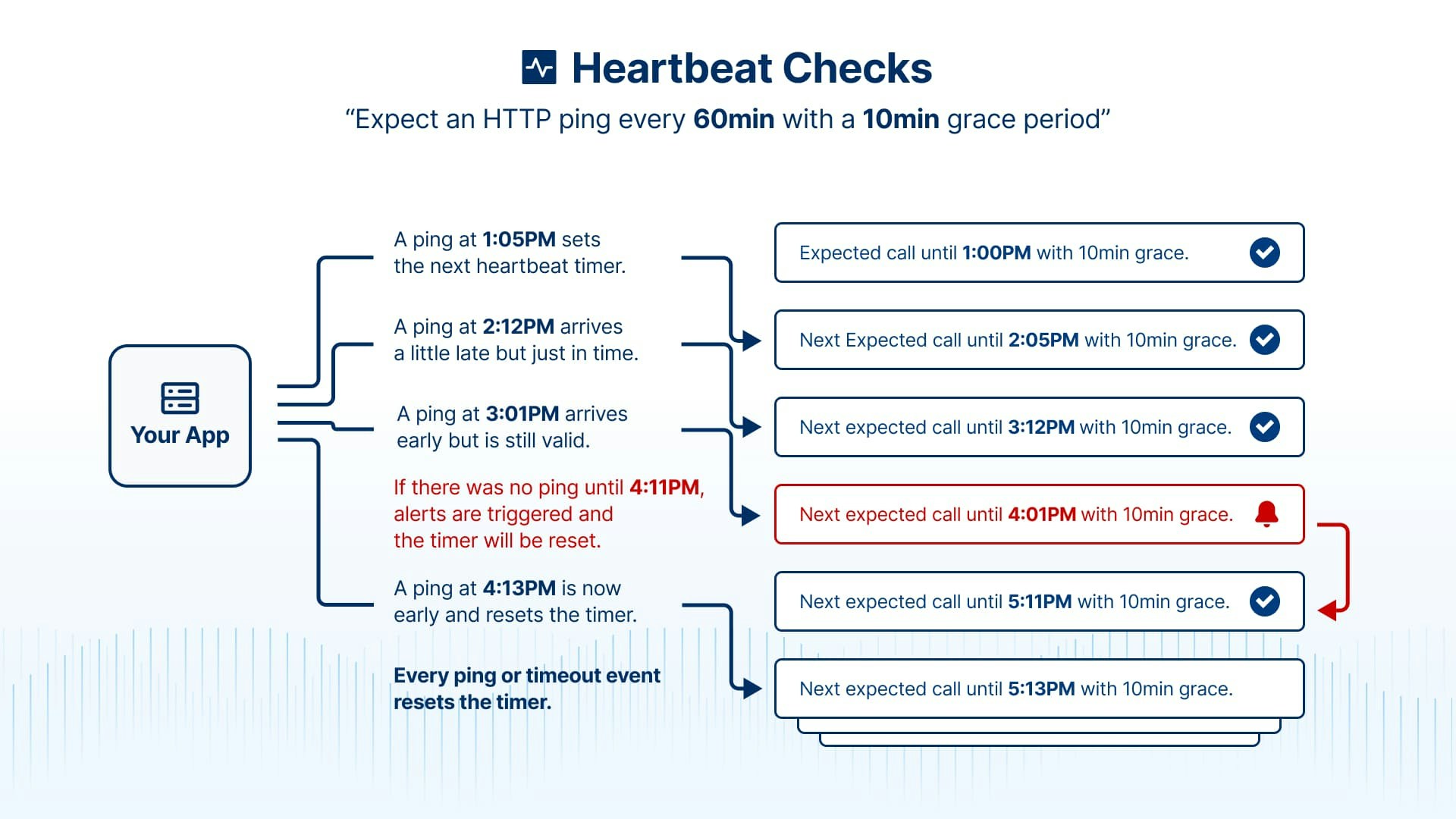
Timer Behavior
The heartbeat timer works predictably:
- First ping starts the timer - When you send the first ping, monitoring begins
- Each ping resets the timer - Every successful ping resets the countdown
- Alerts also reset the timer - After an alert fires, the timer restarts
- Deactivation resets everything - Pausing and resuming a monitor restarts timing
This means if your job is supposed to run every 6 hours but runs late at hour 7, the next ping will be expected at hour 13 (7 + 6), not hour 12.
Metrics
Heartbeat monitors provide different metrics and insights than other types of checks and monitors:
- Ping History: Timeline of when pings were received
- Missed Pings: Gaps where expected pings didn’t arrive
- Alert Timeline: When alerts were triggered and resolved
- Source Tracking: Which systems or processes sent pings
Heartbeat metrics are also available via the Prometheus V2 integration, including dead man’s switch gauges for alerting in Grafana when a ping is overdue.
Remember: Heartbeat monitors detect when jobs fail to complete, but they can’t tell you why a job failed. Combine heartbeat monitoring with application logging and error tracking for complete observability.
Manual pings
You can manually send pings via the Checkly UI. Use this to start the check timer when a check is first created or to silence alarms.
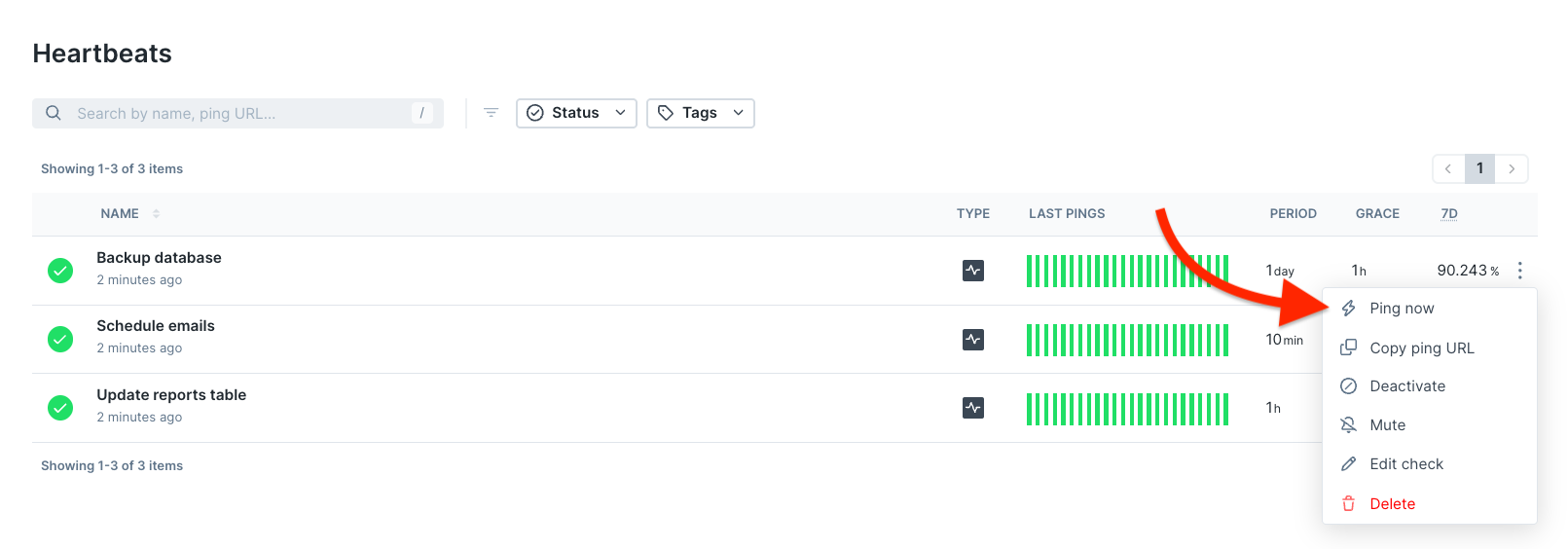
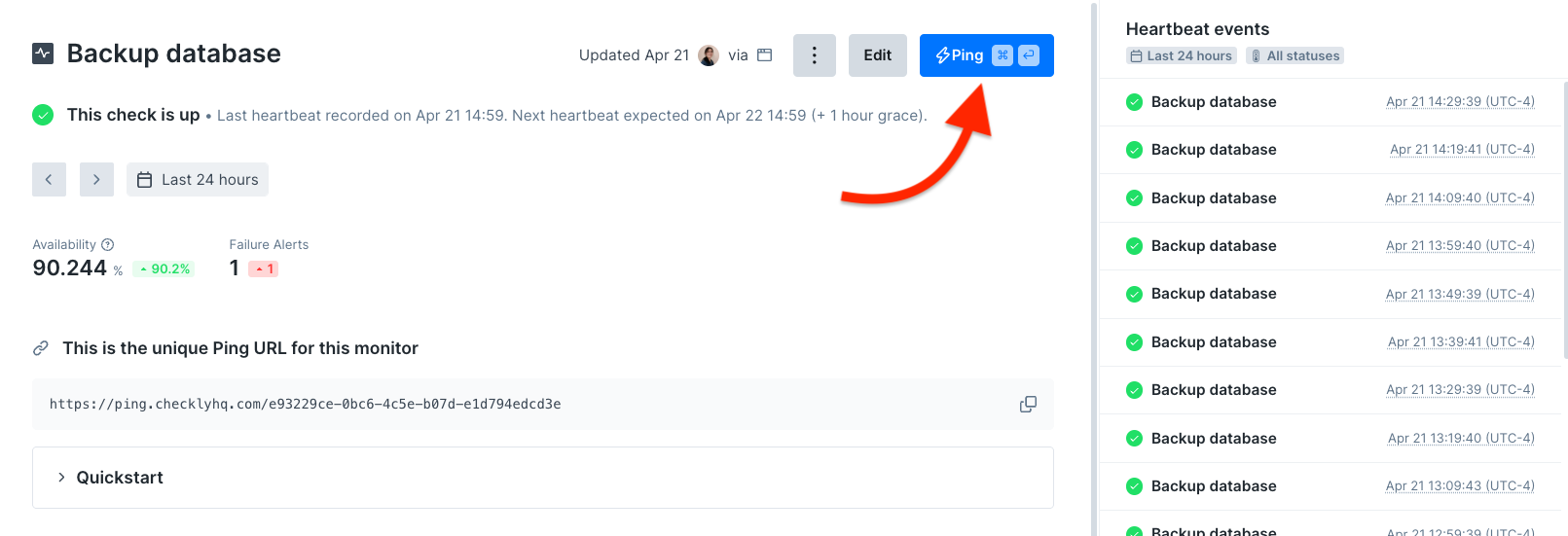 “Ping now” is also available in the quick menu in your list of Heartbeat monitors.
“Ping now” is also available in the quick menu in your list of Heartbeat monitors.
Heartbeat Monitor Results
Heartbeat monitor results show information about the ping request, like when it was recieved and its source.
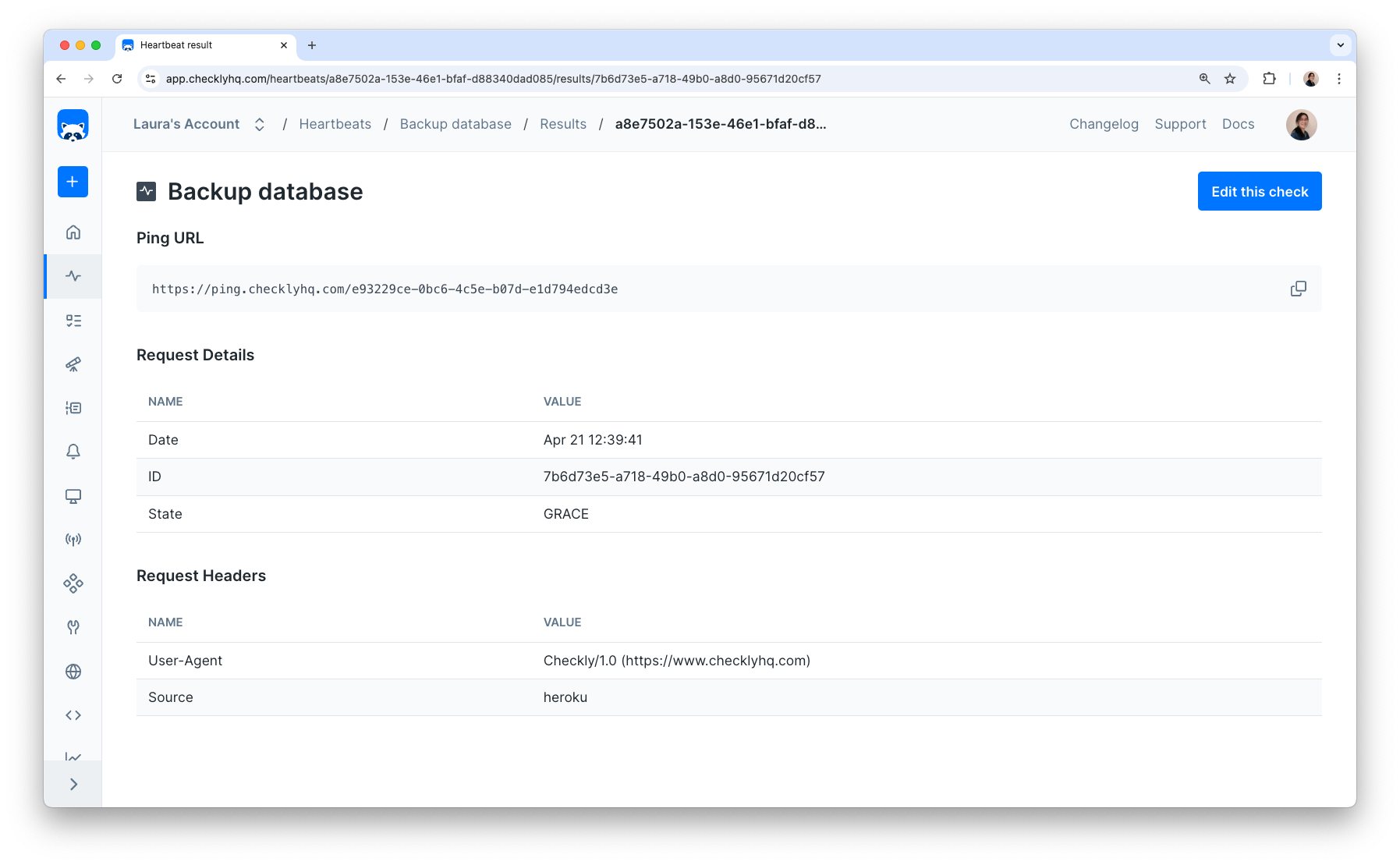 The state indicates when your scheduled job pinged the Heartbeat monitor, relative to the expected time:
The state indicates when your scheduled job pinged the Heartbeat monitor, relative to the expected time:
| State | Description |
|---|
EARLY | Ping recieved before the expected time |
RECEIVED | Ping recieved right at the expected time |
GRACE | Ping recieved after the expected time, during the grace period |
LATE | Ping recieved during the few seconds between the end of the grace period and before the monitor is marked as failing. This is very rare |
FAILING | No ping recieved by the end of the grace period. Indicates a failing Heartbeat monitor |
origin and referer request headers.
Best Practices
Always include timeout and retry options:
# Good: With timeout and retries
curl -m 5 --retry 3 https://ping.checklyhq.com/your-id
# Bad: No timeout or retry protection
curl https://ping.checklyhq.com/your-id
# Good: Ping only after success
try:
run_backup()
upload_to_s3()
# Only ping if everything succeeded
requests.get(ping_url, timeout=5)
except Exception as e:
# Don't ping on failure - let heartbeat alert
log_error(e)
curl -H "Origin: backup-server-01" https://ping.checklyhq.com/your-id