Types of Incidents
Understanding the different types of incidents is key to managing them well. Here are the main types:- Service Outages: These are big problems where a key service stops working. For example, if the power goes out. These need quick action and teamwork to fix.
- Performance Degradation: This happens when a service is still working but not as well as it should. For instance, if a website loads very slowly. It’s important to find and fix the cause fast to keep the service good.
- Security Incidents: These involve threats to the safety of a company’s IT systems, like a data leak. They need special care to protect important information.
- User Issues: These are problems reported by users which, while they may not be caused by a systemic failure on your service’s part, are still affecting multiple users. For example, internet weather affecting a large region, or common user confusion with a new feature or account regulation. A final example would be multiple users who have been affected by malware, which is in turn affecting your service.
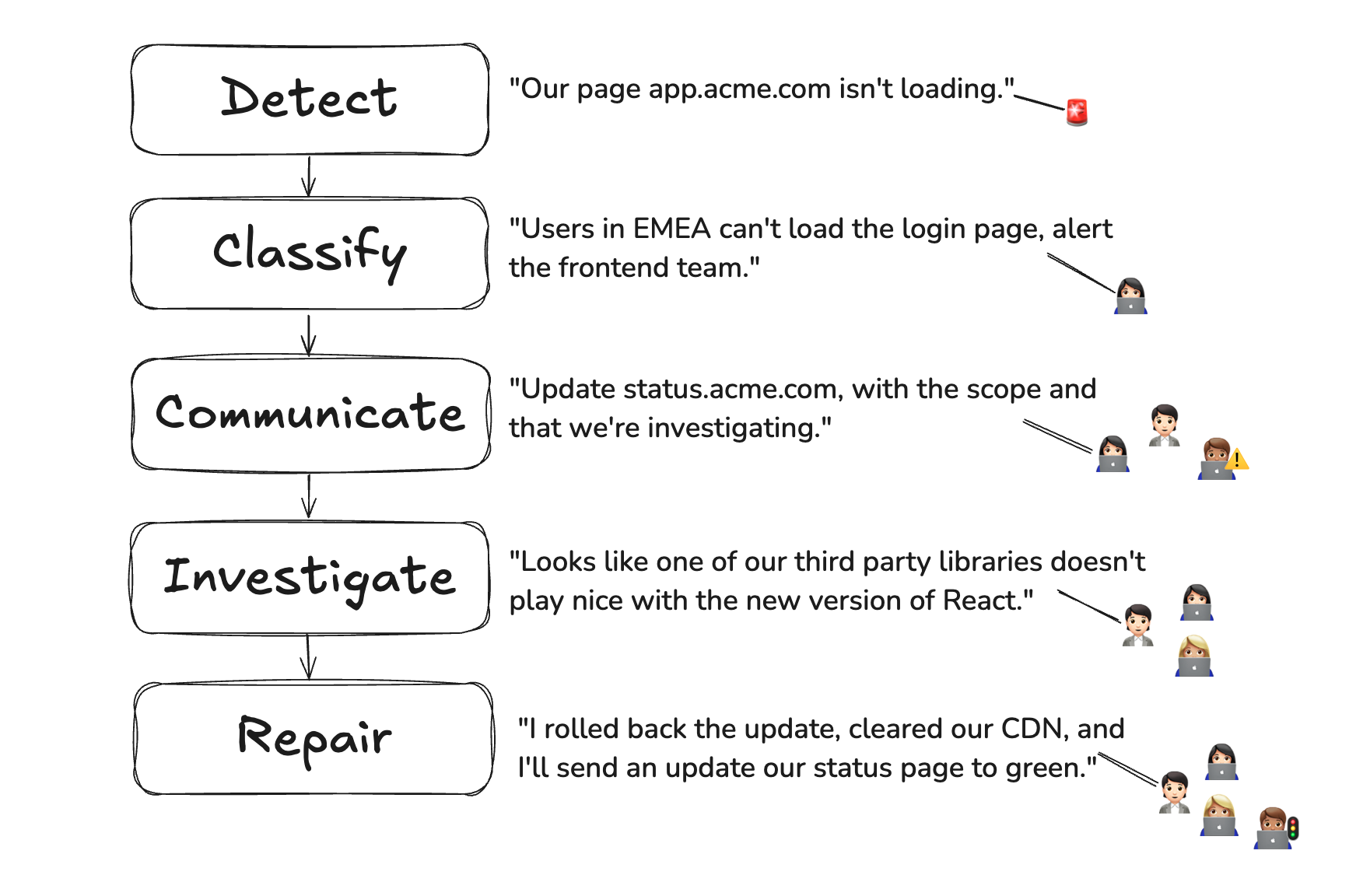
Stages of Incident Response
The incident response process helps teams handle problems quickly and effectively. As noted in the list, some stages may not happen in this order; for example the incident may be closed and reviewed with a root cause resolution not being deployed until later. Here are the key stages:- Identify the Incident: The first step is to notice the problem. This could be a user reporting an issue or an alert from a monitoring system. The team needs a clear way to know when something is wrong.
- Classify the Incident and Determine its Scope: Once the issue is identified, it is recorded in a system. The team then decides how serious it is and who should handle it. On small teams this will generally be a choice between a level 2 incident handled by the on-call engineer and Support/Sales to handle customer communication; and a level 1 incident handled by pretty much everybody.
- Communicate with Users: Whether it’s through a manual update process, a social media update, or an automated status page, once the incident has been classified and the scope determined it’s time to talk to your users (some teams may choose to be more targeted if the failure only affects a small subset of users).
- Remediate the Failure: In some cases it may be possible to remediate the problem before fully diagnosing the cause. For example, a user-reported bug that is easy to reproduce, that starts being reported one hour after a major code deployment, can likely be remediated with a rollback. This can be done before understanding exactly why the recent deployment caused this error.
- Diagnose the Incident: The team investigates to find the root cause of the problem. At this
- Repair the Issue: Once the root cause is known, the team fixes the issue. This could mean adding more resources, fixing a network problem, or applying a permanent solution.
- Close and Review the Incident: After the problem is solved, the team closes the incident and reviews what happened. This helps them learn from the issue and improve for the future.
Best Practices of incident response
Each of the stages of incident response has associated best practices:- Don’t let your users be the ones reporting incidents: whether it’s through monitoring with OpenTelemetry or automated checks with a synthetics tool like Checkly, you don’t want to have any type of failures be reported by users as a matter of course.
- Classify the Incident and Determine its Scope: Once the issue is identified, it is recorded in a system. The team then decides how serious it is and who should handle it. On small teams this will generally be a choice between a level 2 incident handled by the on-call engineer and Support/Sales to handle customer communication; and a level 1 incident handled by pretty much everybody.
- Communicate with Users: Whether it’s through a manual update process, a social media update, or an automated status page, once the incident has been classified and the scope determined it’s time to talk to your users (some teams may choose to be more targeted if the failure only affects a small subset of users).
- Remediate the Failure: In some cases it may be possible to remediate the problem before fully diagnosing the cause. For example, a user-reported bug that is easy to reproduce, that starts being reported one hour after a major code deployment, can likely be remediated with a rollback. This can be done before understanding exactly why the recent deployment caused this error.
- Diagnose the Incident: The team investigates to find the root cause of the problem. Depending on how well our remediation steps worked, root cause analysis may wait until after the incident, or be held off until working hours the next morning. However, if effective remediation isn’t available (for example if a simple restart hasn’t fixed things), you may be trying to diagnose root causes under time pressure. Key tools include Checkly Traces to connect OpenTelemetry traces with synthetics data.
- Repair the Issue: Once the root cause is known, the team fixes the issue. This could mean adding more resources, fixing a network problem, or applying a permanent solution.
- Close and Review the Incident: After the problem is solved, the team closes the incident and reviews what happened. This helps them learn from the issue and improve for the future.