Setting Up Observability with OpenTelemetry
Instrumentation
To begin, you need to instrument your code with OpenTelemetry client libraries. These libraries help generate telemetry signals such as logs, metrics, and traces from your application.Data Collection and Processing
Once the telemetry data is generated, it can be exported directly to a backend or processed through the OpenTelemetry Collector. Using a collector helps offload the responsibility of data management from the application, making it easier to handle different data pipelines. To use the collector, after setting up your first collector instance, you’ll configure your application’s OpenTelemetry installation to send data to your collector, generally via the OpenTelemetry protocol or OTLP.Deployment Options
The OpenTelemetry Collector can be deployed in multiple ways:- As an agent: Installed on the same host as the application reporting data. Generally one collector per application
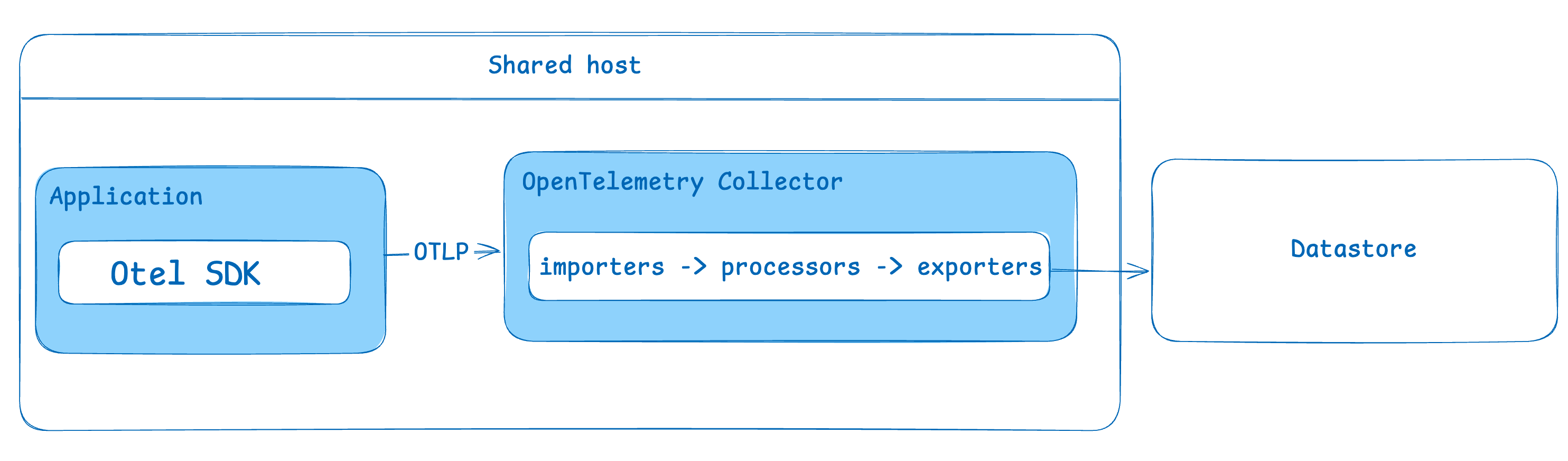
- As a standalone service with a gateway: Runs independently, receiving telemetry from multiple sources, possibly with a load balancer.
Data Storage
The OpenTelemetry collector is fully stateless, it produces no dashboards and stores no data. It doesn’t even create an API endpoint to get status information. The collector is only useful when transmitting data, so your OpenTelemetry data needs somewhere to go. SaaS tools like Coralogix can receive your data, or you’ll need to set up your own datastore with something like Prometheus.OpenTelemetry and the CNCF
The OpenTelemetry framework is part of the Cloud Native Computing Foundation (CNCF) and aims to standardize the handling of telemetry data. It provides a consistent interface to collect and export data across many programming languages. The collector is an important part of this mission, since a standardized proxy for all OpenTelemetry data helps different teams in different languages form a shared understanding of how their data is collected, processed, and transmitted.Key Functions of the OpenTelemetry Collector
- Collection: Collects telemetry data in various formats from multiple sources.
- Processing: Applies transformations, such as sampling, batching, or removing sensitive data.
- Exporting: Sends telemetry data to different backend systems.
Components of the OpenTelemetry Collector
- Receivers: These accept data into the collector. Common formats include OTLP, Jaeger, and Prometheus.
- Processors: Apply operations on the data, such as batching, retries, or adding metadata. Processors can also handle privacy-related tasks like removing personally identifiable information (PII). See our advanced guide on filtering data with the OpenTelemetry collector.
- Exporters: These send data to backends. You can send metrics to tools like Prometheus and traces to Jaeger or other supported systems.
Configuring the OpenTelemetry Collector
The configuration is managed via a YAML file, defining how receivers, processors, and exporters are connected in pipelines.Example Configuration
Receivers
Processors
Exporters
Pipelines
Backend Options for OpenTelemetry Metrics and Traces
After setting up the OpenTelemetry Collector, you will need tools to visualize and analyze the data. Prometheus is a popular choice for storing and querying metrics, while Grafana can visualize these metrics with dashboards. For tracing data, Jaeger is commonly used.- Prometheus: Ideal for collecting and storing time-series metrics.
- Grafana: A visualization tool compatible with Prometheus metrics.
- Jaeger: Focuses on distributed tracing for microservices-based applications.
Use Cases
The OpenTelemetry Collector is useful for:- Redacting sensitive data: Ensure compliance with privacy and security standards.
- Batching telemetry data: Compress data and reduce the number of outgoing connections.
- Customizing telemetry pipelines: Modify attributes, transform metrics, or sample traces to suit your observability needs.
FAQs
Do I have to deploy an OpenTelemetry collector?
You don’t have to use a collector to gather OpenTelemetry data. In the simplest example where you’re monitoring a single monolithic application, the difference without a collector would be at the time of reporting data: instead of traces, logs, and metrics going to a collector; data would travel directly to the storage endpoint. If you’re starting out with a demo project, or you’re only using OpenTelemetry for a very limited purpose (for example you’re only implementing OpenTelemetry to send a few key traces to Checkly), it may make sense not to use a collector at all.What is the difference between the OpenTelemetry Agent and Collector?
There isn’t an ‘agent’ as such that’s part of the OpenTelemetry model. As mentioned above the collector may be deployed in an ‘agent’ pattern where the collector is running on the same host as the application, but the term ‘agent’ is a little overloaded in observibility and requires brief disambugation. The other part of observability sometimes called an ‘agent’ is a process running within an application that receives data on the system. For example, automatic instrumentation of Java applications is made possible by the standardjavaagent jvm argument. Using an agent to observe your application will depend on your language library’s implementation.
The collector is not an ‘agent’ running within an application, it runs outside your application and collects and forwards data.
How does OpenTelemetry compare with Prometheus?
Prometheus is focused on metrics, using a pull model for data collection. OpenTelemetry, on the other hand, is a broader framework that handles logs, metrics, and traces and supports multiple backends.What is OpenTelemetry’s collector-contrib?
Thecollector-contrib repository offers community-contributed components that extend the capabilities of the core OpenTelemetry Collector. These additions provide more receivers, processors, and exporters to handle different telemetry scenarios.