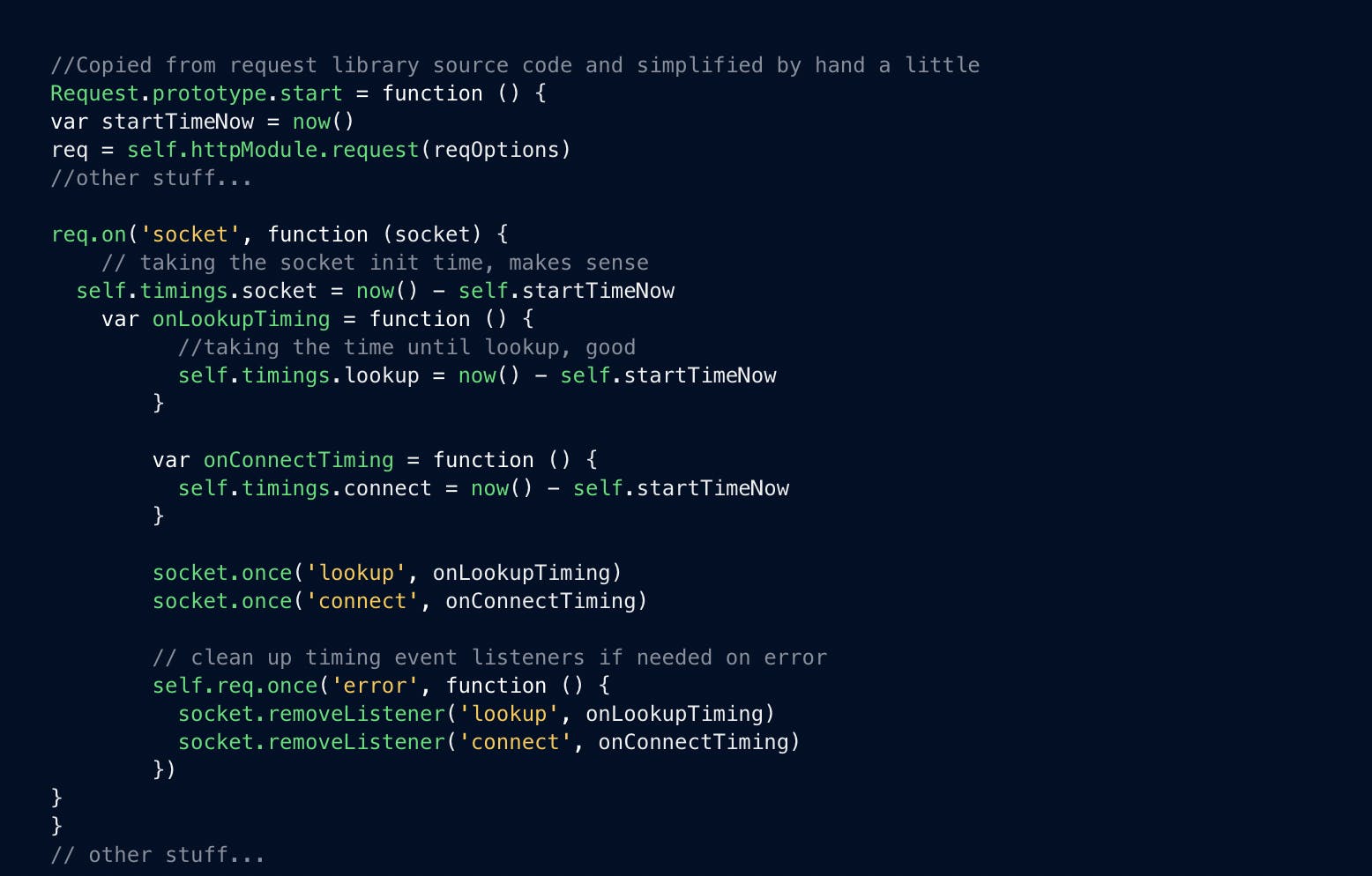
Table of contentsBisecting the problemProduct Research: How would you build a proper DNS check?Building a quick DNS Check with NodeJS and DigReproducing things that almost never happen with ChecklySet up tcpdump on a private location and wait some moreNow for the fix!