tl;dr: Node by default doesn’t implement the Happy Eyeballs algorithm for web requests, and therefore if a server has a broken IPv6 address that responds first, it will usually fail.
This is the story of how an otherwise working server was completely unavailable for users in a geographic region, and how in one very specific way Node doesn’t handle requests as well as an Opera browser from 2011.
How we got here: the Checkly Coralogix integration
By now you’ve heard of the Checkly Coralogix integration, part of a broader strategy at Checkly of embracing OpenTelemetry and using Checkly to give you insight into backend services’ performance. Released a couple of months ago, this integration lets you set some configuration options in Checkly to send our synthetic monitoring (a fancy term for scheduled end-to-end tests) traces to Coralogix. Once the integration is enabled you’ll see connected traces linked from the Checkly interface:

A Checkly trace with a link to Coralogix
And you can find the detailed reports from your synthetic monitoring in the Coralogix dashboard. This feature, combined with our CLI and support for Monitoring as Code, mean that your whole team can be involved in a shift left of monitoring, sharing monitoring results more broadly and making multiple teams aware of monitoring data on systems that were previously a black box.
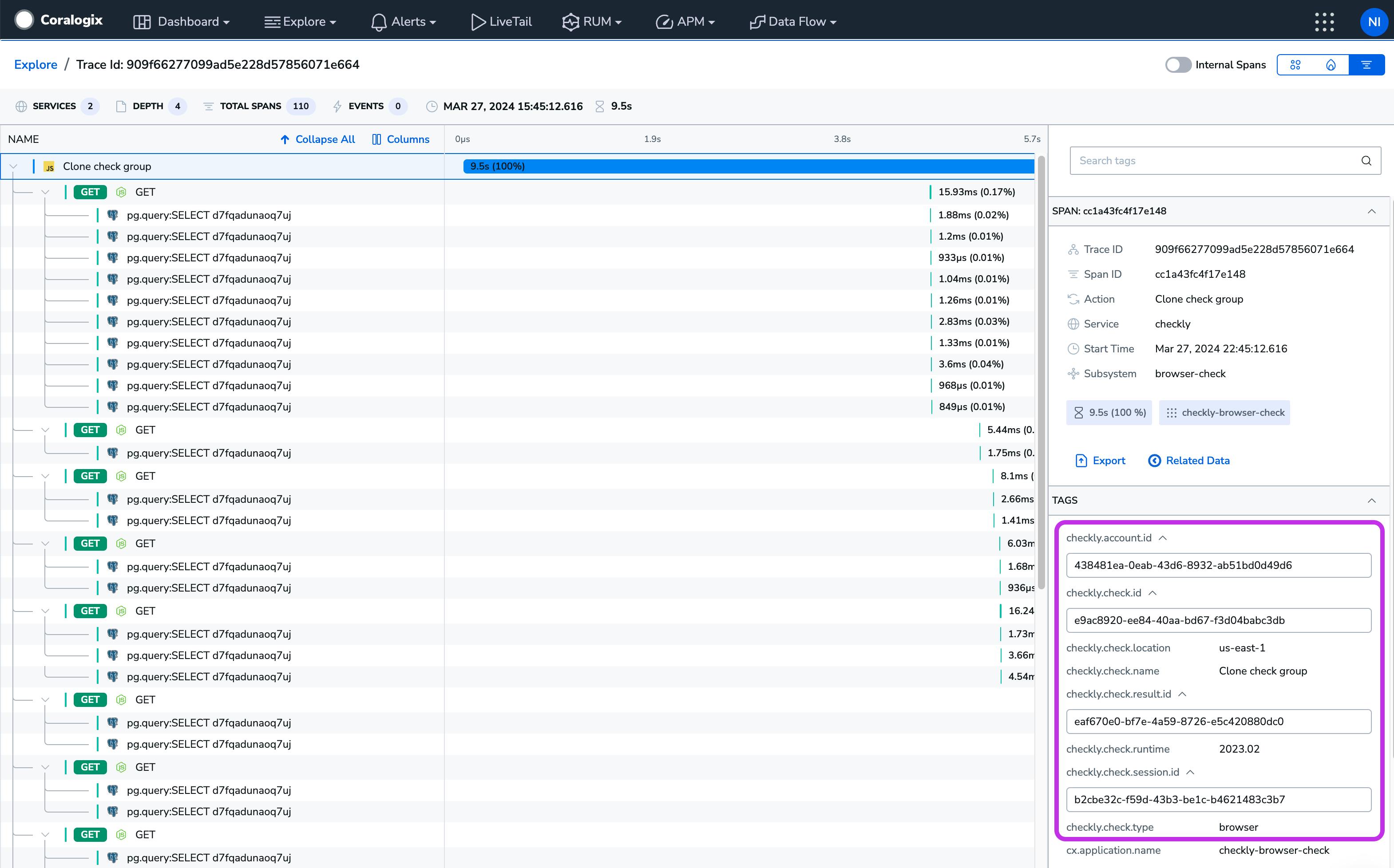
A backend trace kicked off with a Checkly request, including the information from the Checkly runner
The problem: it worked fine for us, but not in US-East-1
When testing the integration feature, one of the steps was selecting the Coralogix server where Checkly should send data, based on its region. For us in EU-2 it was working great, but when the Coralogix VP of Product tried it, it wasn’t working at all. We quickly found the difference: he was using US-EAST-1 and that was failing consistently. What could the matter be?
As this transition happened around the time we shifted to ephemeral pods, we were tempted to blame architectural changes as the culprit, we couldn’t find anything suggestive of how the change would break this connection for one region. We felt confident that the different AWS regions didn’t have way different network architectures, and our runners were otherwise totally happy talking to different regions.
Getting into the weeds: tcpdumps
While we were investigating the network issues, we added an internal feature to our Checkly runner that allowed us to look at a full tcpdump for an API request. It was after doing this that we saw something that surprised us: every request from our runner sent two DNS queries. That can’t be right… can it?
It can’t be DNS
Okay, this feels like a story about as well-known as the origins of Spider-Man but, let’s do this one more time: weren’t we supposed to get rid of IPv4 around the time Tobey Maguire took off the spandex suit?

I guess, just like Spider-Man, there are some stories we can’t stop repeating
Short version: we were supposed to switch everything over to IPv6, we haven’t. Progress is being made but many many things have DNS entries for both an IPv4 and IPv6 address.
Slightly longer: Think of the internet as a giant phone book. IPv4 is like those old landlines, while IPv6 is the newfangled smartphone. Now, when your computer wants to make a call (connect to a website), it has to decide which number to dial. IPv4 numbers are found under “A” in the phone book (DNS records), while IPv6 numbers are under “AAAA”—because, you know, four A’s are better than one.
Here’s where Node.js comes into play. It looks up both numbers separately and, depending on its version, it either sticks to the old reliable landline (IPv4) or grabs whichever number rings first. In Node.js 18 and earlier, it was all about that landline life, preferring IPv4. But starting from Node.js 18, it became a bit more open-minded with the “verbatim” setting, meaning it just grabs the first number that pops up, whether it’s IPv4 or IPv6.
However, there’s a catch. If you get an IPv6 number but your shiny smartphone (IPv6) has a broken signal, you’re stuck with a bad connection. Browsers, being the smarty-pants they are, foresaw this and implemented the “Happy Eyeballs” algorithm.
“Happy Eyeballs” in a nutshell
I want to take one step back and summarize “Happy Eyeballs” since, if you’re implementing HTTP from scratch, you should know this too!
Imagine you're at a buffet, and there are two lines—one for pizza and one for crab legs. You love both, so you jump into whichever line is moving faster. That’s the "Happy Eyeballs" algorithm for browsers. Instead of waiting around for one internet connection to get its act together, your browser checks out both IPv4 and IPv6 at the same time. The standard implementation will prefer ipv6 over ipv4 and if ipv4 responds first, it will wait up to 50ms, to see if the ipv6 will respond within that time.
The idea is to keep your eyes—and connections—on the prize, so you don’t end up staring at a loading screen longer than necessary. Notably, this algorithm should be fault-tolerant. If the faster of the two connections isn’t returned, the slower one will work. After all even if we get to the front of the buffet and they’re out of crab legs, we still want to eat, so pizza it is.
Happy eyeballs is more than a suggestion it’s an internet standard, so we generally expect it to happen everywhere, but the surprise was that this wasn’t happening by default on Node.
…it was DNS
This particular failure state required specific conditions. The AAAA IPv6 entry had to be available but broken, and the IPv6 had to come back from DNS faster for the request to fail. In our case we were lucky that the problem, if the A records sometimes came back first it would cause an intermittent failure, and it’s hard to imagine how long that would have taken to diagnose!
IPv6 on Node: Pobody’s Nerfect
There’s some discussion on GitHub about why Node doesn’t implement this algorithm the way browsers do, and how changing Node’s behavior now can have unexpected effects. Even the current 20.1 release that does implement “Happy Eyeballs” has some unexpected effects.
An article I’m working on to for next week is on why Checkly is a Node shop. Any time anything doesn’t work on Node someone tells me I should have just used Go, Rust, or a Field-programmable Gate Array instead of the world’s most popular programming language. Is this problem singular to Node? Are Node’s built-in convenience functions a source of unexpected failures? Not really. Any modern language is going to have an HTTP implementation built in. Go has native support for everything from HTTP to composing HTML from templates, so it’s not a special vulnerability in Node that means tiny gaps exist between standard browser behavior and your server’s code execution.
Why Checkly exists: observe your code in the real world
If we want to go broader, we’re also getting to the reason Checkly and Synthetic Monitoring exist at all: application code on a server isn’t a good imitation of web requests coming from a browser. Our Playwright-based Browser checks strive to accurately represent a user’s visual experience, and API checks can run from the same geographies and with the same retry logic as your real requests. To be certain that a service is working as expected, you have to observe it with real requests.
In the end it took nearly a week of investigation to find the problem, and five minutes to fix by configuring our requests. The issue would have been easier to diagnose now, And if you’re curious why we recently announced support for IPv6 requests in our API checks, we identified the need while investigating this issue!
Results: Coralgix & Checkly for all!
As a result of this process, we unblocked our extremely cool Checkly x Coralogix integration for all users. That means more users of Checkly will be able to find insights like the one Jan found using Coralogix and OpenTelemetry that saved thousands of hours of execution time with a tiny optimization.