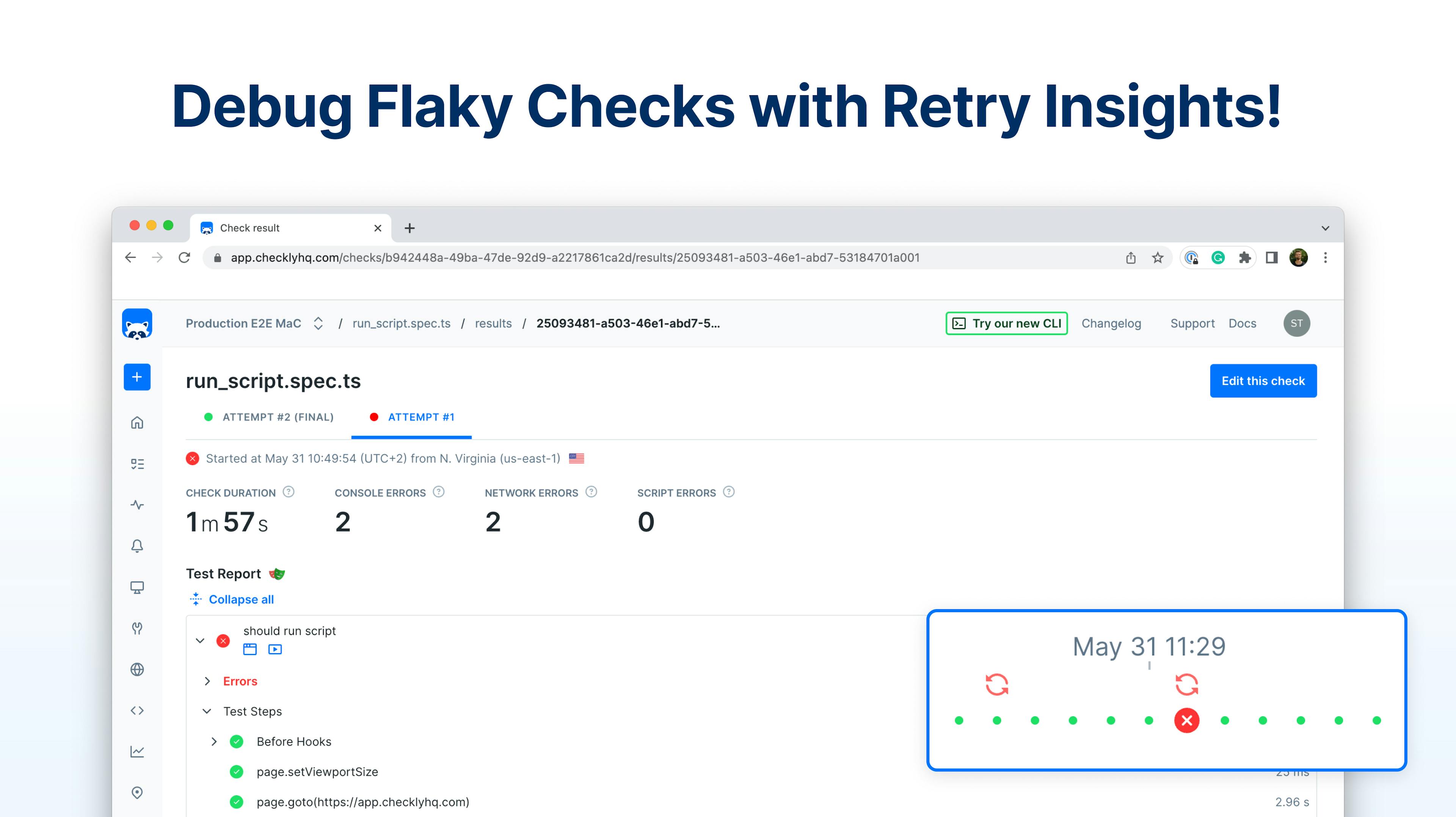
Table of contentsIntroducing Retry InsightsHow Retry Insights will streamline your monitoringCommon reasons for flaky checks