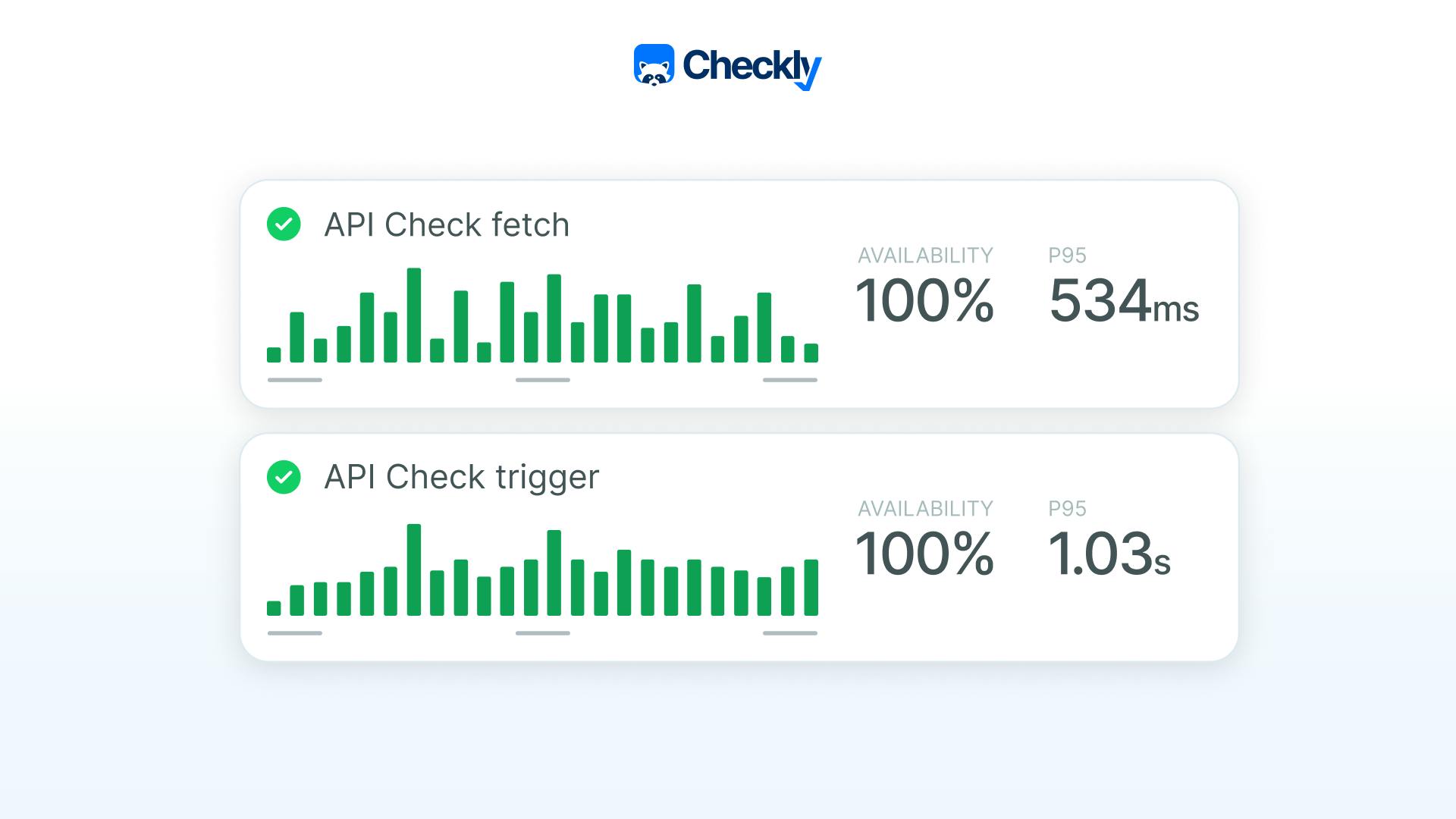
How LinkedIn modernized their monitoring infrastructure with Checkly
LinkedIn, a professional networking platform, manages a vast and complex infrastructure that supports over a billion members worldwide. Operating at this scale brings unique challenges from LinkedIn’s on-premise infrastructure modernizing off legacy components.
To navigate these complexities and improve reliability, LinkedIn partnered with Checkly, leveraging its synthetic monitoring and testing capabilities. Let’s explore the intricacies of LinkedIn’s infrastructure, the modernization initiatives underway, and how Checkly’s Monitoring as Code (MaC) plays a crucial role in enhancing system reliability, reducing incident detection times, and supporting LinkedIn's broader technological goals.
50%
More monitoring coverage
76%
Reduced monitoring cost
1 Min.
Mean Time To Detection
“Checkly made it easier for us to simulate real user behavior and detect failures early in the process.
The flexibility of Checkly made it easier for us to simulate real user behavior and detect failures early in the process, improving our overall monitoring. We’d detect issues within minutes of them becoming prevalent, whereas other solutions took much longer. ”

Senior Staff Engineer - SRE